CAMEX integrates liver scRNA-seq dataset across four species
This tutorial demonstrates that CAMEX achieves competitive integration performance in different cross-species scenarios.
Here, we use a liver scRNA-seq dataset across four species. Processed h5ad files can be downloaded from https://drive.google.com/drive/folders/1rwdjEvWFEFw82a0x2JzMi2jXICbUc5eb?usp=sharing
[1]:
import warnings
warnings.filterwarnings("ignore")
[2]:
import os
import time
import torch
import shutil
import warnings
import argparse
import importlib
import scanpy as sc
import pandas as pd
import numpy as mp
from CAMEX.base import Dataset
from CAMEX.trainer import Trainer
[3]:
from params import PARAMS
[4]:
t1 = time.time()
make log dir
[5]:
time_start = time.strftime("%Y-%m-%d-%H-%M-%S")
log_path = f'./log/{time_start}/'
for k, v in PARAMS.items():
v['time_start'] = time_start
v['log_path'] = log_path
print(log_path)
./log/2024-04-12-16-24-02/
[6]:
os.makedirs(log_path, exist_ok=True)
shutil.copy('params.py', log_path + 'params_current.py')
print(f'time: {time_start}')
time: 2024-04-12-16-24-02
preprocess scRNA_seq data to construct a heterogeneous graph of cells and genes
[7]:
# —————————————————————————————————— 1 preprocess
print('start preprocess')
dataset = Dataset(**PARAMS['preprocess'])
adata_CAMEX = dataset.adata_whole
dgl_data = dataset.dgl_data
start preprocess
raw-liver-human-Martin: reference raw-liver-monkey-Martin: query raw-liver-mouse-Martin: query raw-liver-zebrafish-ggj5: query
Hepatocytes 2705.0 5340.0 2888.0 5594.0
Endothelial 700.0 1455.0 427.0 158.0
fibroblasts 353.0 612.0 413.0 NaN
Cholangio 197.0 365.0 35.0 NaN
Macrophages 170.0 NaN NaN 91.0
Kupffer cells NaN 364.0 154.0 NaN
NK NKT and T cells NaN 199.0 NaN NaN
B Plasma cells NaN 148.0 26.0 NaN
HsPCs NaN NaN 23.0 NaN
[8]:
print('start train')
trainer = Trainer(adata_CAMEX, dgl_data, **PARAMS['train'])
start train
integration
[9]:
trainer.integration()
--------------------------------------------- integration ---------------------------------------------
epoch: 0, loss: 194.20159350501166
epoch: 1, loss: 28.492300934261745
epoch: 2, loss: 28.00826687282986
epoch: 3, loss: 27.758199003007675
epoch: 4, loss: 27.58817916446262
epoch: 5, loss: 27.47245693206787
epoch: 6, loss: 27.325444804297554
epoch: 7, loss: 27.26902151107788
epoch: 8, loss: 27.207756148444282
epoch: 9, loss: 27.12559159596761
[10]:
adata_CAMEX.write_h5ad(log_path + 'adata_CAMEX.h5ad', compression='gzip')
[11]:
t2 = time.time()
[12]:
print(f'time usage: {round(t2-t1)} seconds')
time usage: 300 seconds
analysis
[13]:
log_path
[13]:
'./log/2024-04-12-16-24-02/'
[14]:
adata_CAMEX = sc.read_h5ad(log_path + 'adata_CAMEX.h5ad')
adata_CAMEX
[14]:
AnnData object with n_obs × n_vars = 22417 × 2000
obs: 'cell_ontology_class', 'batch', 'n_genes_by_counts', 'total_counts', 'cell_ontology_class_num', 'cell_class', 'cell_class_num'
var: 'n_cells_by_counts', 'mean_counts', 'pct_dropout_by_counts', 'total_counts', 'highly_variable', 'means', 'dispersions', 'dispersions_norm', 'highly_variable_nbatches', 'highly_variable_intersection', 'mean', 'std'
uns: 'cell_type', 'data_order', 'dataset_description', 'dataset_type', 'hvg', 'log1p', 'neighbors', 'pca'
obsm: 'X_CAMEX_Integration', 'X_pca'
varm: 'PCs'
layers: 'counts'
obsp: 'connectivities', 'distances'
[15]:
adata_CAMEX.obsm['X_CAMEX_Integration'].shape
[15]:
(22417, 128)
[16]:
sc.pp.neighbors(adata_CAMEX, use_rep='X_CAMEX_Integration')
[17]:
sc.tl.umap(adata_CAMEX)
[18]:
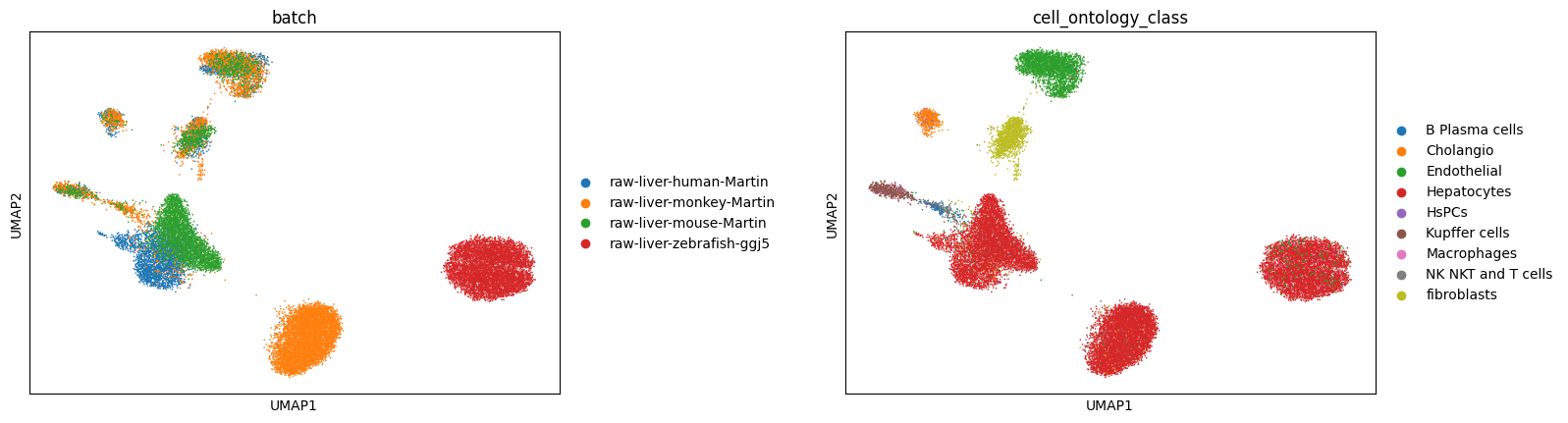
sc.pl.umap(adata_CAMEX, color=['batch', 'cell_ontology_class'], wspace=0.4)
[19]:
adata_CAMEX.obs.loc[:, 'batch'].unique()
[19]:
['raw-liver-human-Martin', 'raw-liver-monkey-Martin', 'raw-liver-mouse-Martin', 'raw-liver-zebrafish-ggj5']
Categories (4, object): ['raw-liver-human-Martin', 'raw-liver-monkey-Martin', 'raw-liver-mouse-Martin', 'raw-liver-zebrafish-ggj5']
Harmony
We provide an expression matrix aligned by one-to-one homologous genes
[20]:
adata_CAMEX = sc.read_h5ad(log_path + 'adata_CAMEX.h5ad')
adata_CAMEX
[20]:
AnnData object with n_obs × n_vars = 22417 × 2000
obs: 'cell_ontology_class', 'batch', 'n_genes_by_counts', 'total_counts', 'cell_ontology_class_num', 'cell_class', 'cell_class_num'
var: 'n_cells_by_counts', 'mean_counts', 'pct_dropout_by_counts', 'total_counts', 'highly_variable', 'means', 'dispersions', 'dispersions_norm', 'highly_variable_nbatches', 'highly_variable_intersection', 'mean', 'std'
uns: 'cell_type', 'data_order', 'dataset_description', 'dataset_type', 'hvg', 'log1p', 'neighbors', 'pca'
obsm: 'X_CAMEX_Integration', 'X_pca'
varm: 'PCs'
layers: 'counts'
obsp: 'connectivities', 'distances'
[21]:
adata_4species_CAMEX = sc.AnnData(X=adata_CAMEX.raw.X, obs=adata_CAMEX.obs, var=adata_CAMEX.raw.var, uns=adata_CAMEX.uns)
adata_4species_CAMEX.raw = adata_4species_CAMEX
adata_4species_CAMEX.layers['counts'] = adata_CAMEX.raw.X.toarray()
[22]:
adata_4species_CAMEX.X.max()
[22]:
657.0
[23]:
sc.pp.normalize_total(adata_4species_CAMEX)
sc.pp.log1p(adata_4species_CAMEX)
WARNING: adata.X seems to be already log-transformed.
[24]:
adata_4species_CAMEX.X.max()
[24]:
6.062208
[25]:
sc.pp.highly_variable_genes(adata_4species_CAMEX, batch_key='batch', subset=True, n_top_genes=2000)
adata_4species_CAMEX
[25]:
AnnData object with n_obs × n_vars = 22417 × 2000
obs: 'cell_ontology_class', 'batch', 'n_genes_by_counts', 'total_counts', 'cell_ontology_class_num', 'cell_class', 'cell_class_num'
var: 'highly_variable', 'means', 'dispersions', 'dispersions_norm', 'highly_variable_nbatches', 'highly_variable_intersection'
uns: 'cell_type', 'data_order', 'dataset_description', 'dataset_type', 'hvg', 'log1p', 'neighbors', 'pca'
layers: 'counts'
[26]:
sc.pp.pca(adata_4species_CAMEX)
sc.pp.neighbors(adata_4species_CAMEX)
sc.tl.umap(adata_4species_CAMEX)
[27]:
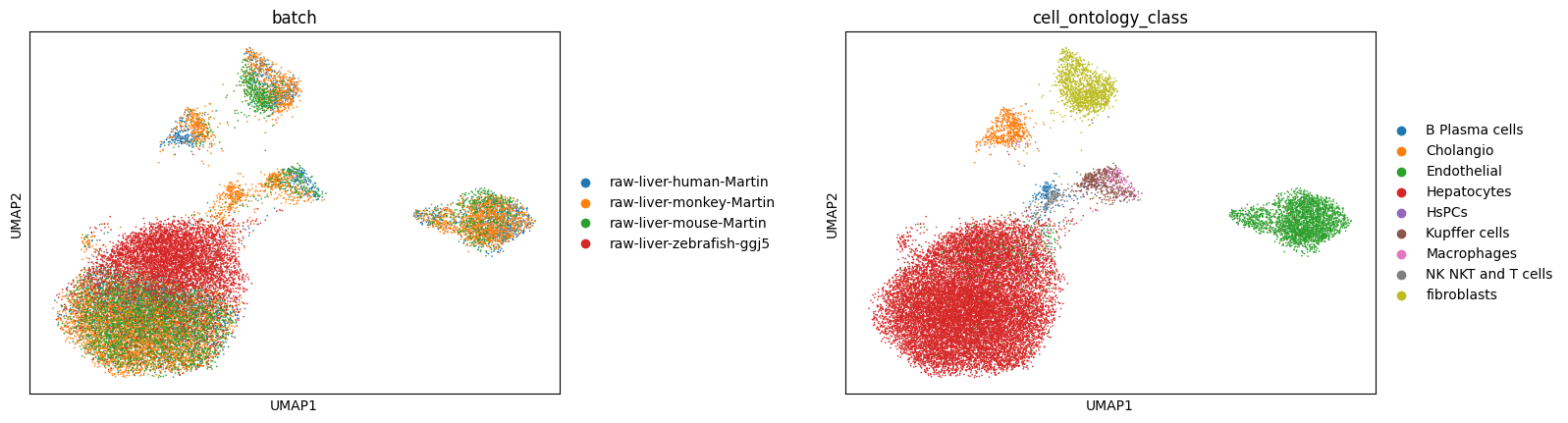
sc.pl.umap(adata_4species_CAMEX, color=['batch', 'cell_ontology_class'], wspace=0.5)
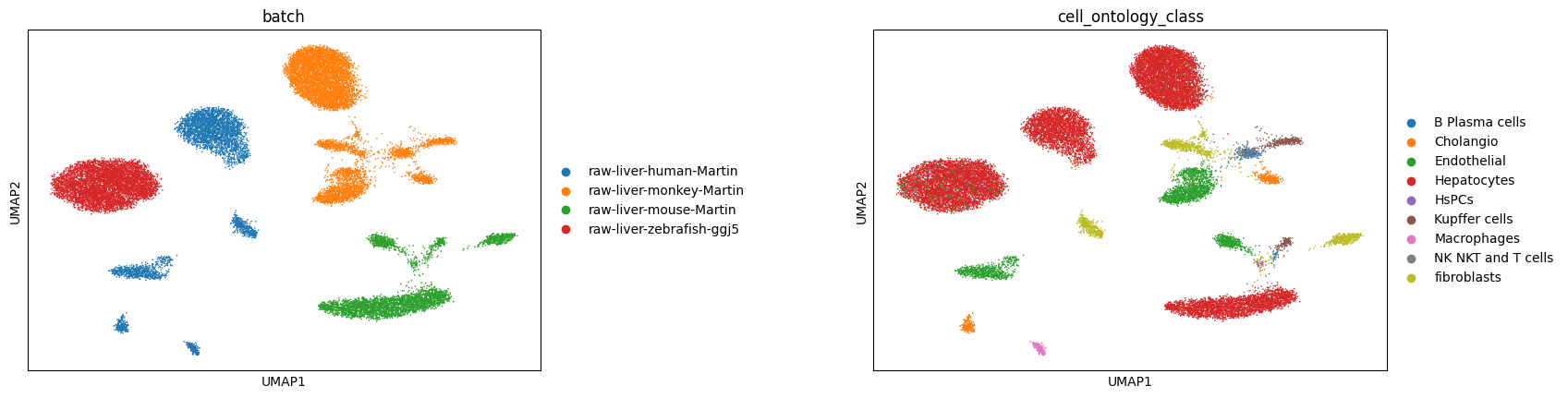
harmnoy integrate
[28]:
import scanpy.external as sce
[29]:
adata_harmony = adata_4species_CAMEX.copy()
adata_raw = adata_4species_CAMEX.copy()
adata_harmony.X.max(), adata_raw.X.max()
[29]:
(5.3807874, 5.3807874)
[30]:
sce.pp.harmony_integrate(adata_harmony, 'batch')
2024-04-12 16:30:23,773 - harmonypy - INFO - Computing initial centroids with sklearn.KMeans...
2024-04-12 16:30:29,603 - harmonypy - INFO - sklearn.KMeans initialization complete.
2024-04-12 16:30:29,703 - harmonypy - INFO - Iteration 1 of 10
2024-04-12 16:30:35,813 - harmonypy - INFO - Iteration 2 of 10
2024-04-12 16:30:40,593 - harmonypy - INFO - Converged after 2 iterations
[31]:
sc.pp.neighbors(adata_harmony, use_rep='X_pca_harmony')
sc.tl.umap(adata_harmony)
sc.pl.umap(adata_harmony, color=['batch', 'cell_ontology_class'], wspace=0.4)